并发构建数到达12个时,把hub-server搞挂了,然后所有的构建都失败了。

可以给一下pod的状态,看看hub-server是否有重启。 如果有,describe一下看看是否是OOM等原因重启。如果还不是,使用-p获取上一个pod的日志,发一下
有重启的,我现在把内存提高到2G了,目前没有这个报错,不过出现了一些其他奇怪的报错。
比如构建日志里正常,但是任务显示为失败,构建被终止。
或者构建日志里看到已经构建完成了,然是任务显示确实超时。
或者显示拉取gitlab代码失败。
这些是在并发构建超过24个构建的时候发现的问题
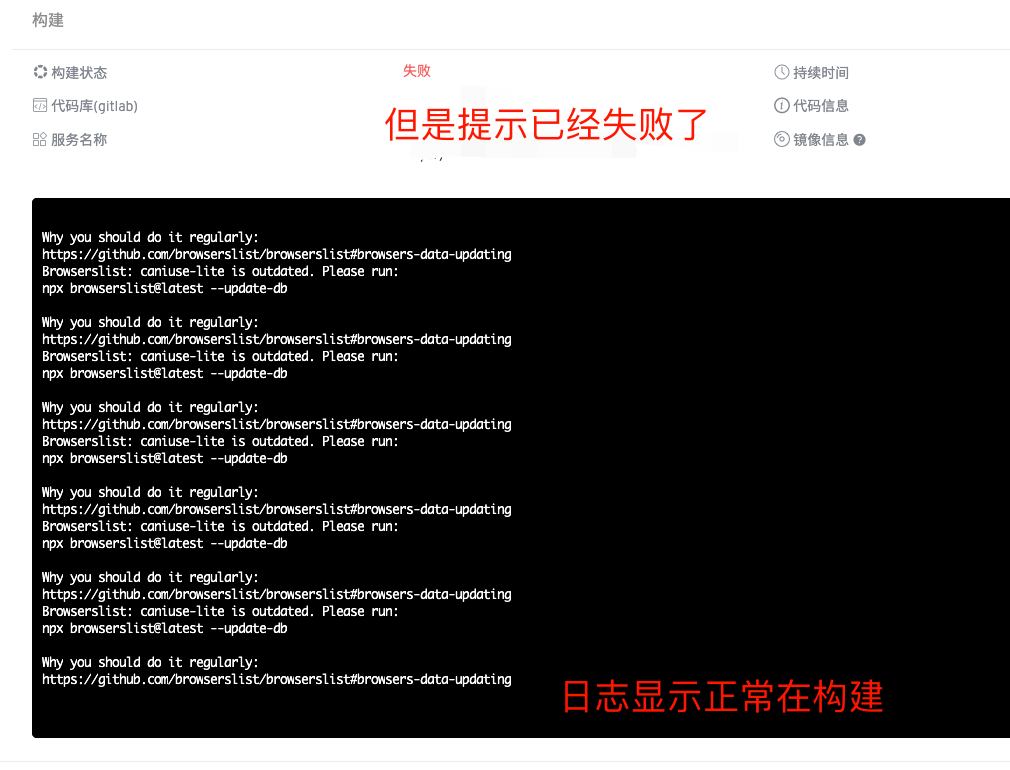
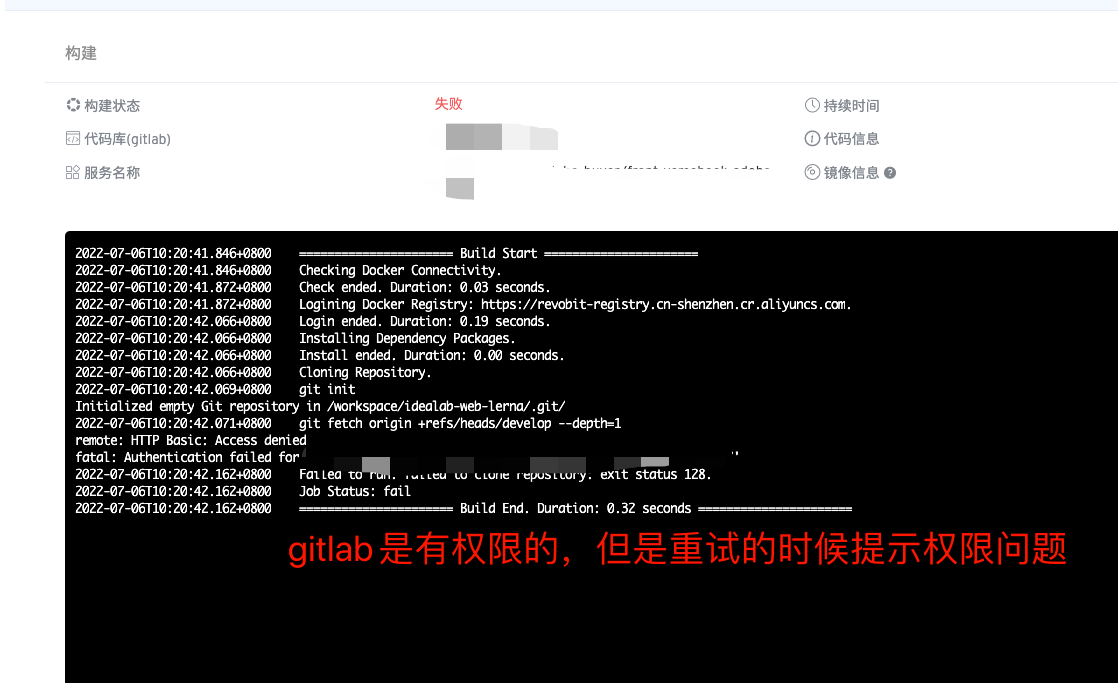
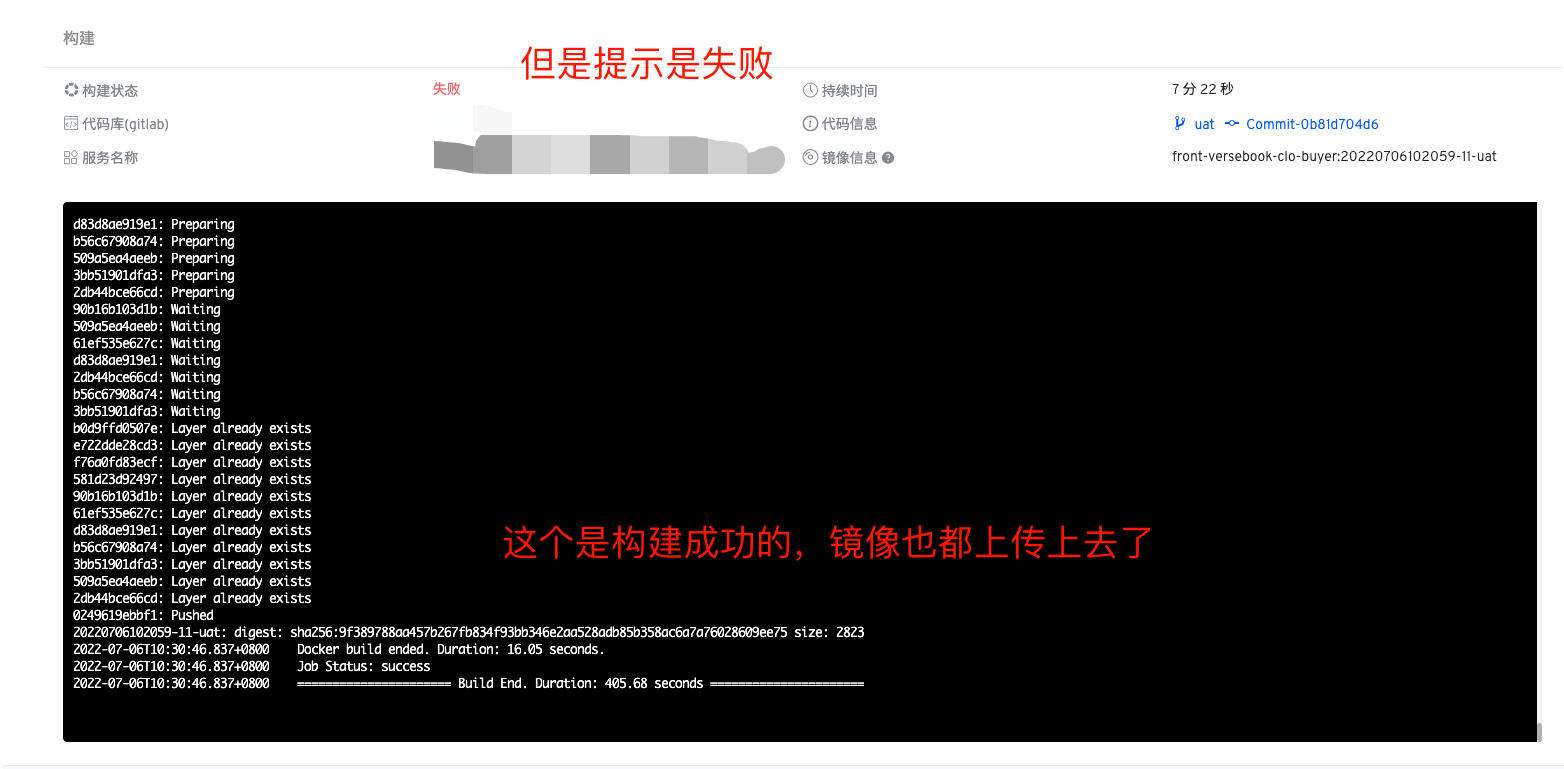
这些是我将同时构建数提升到24个的时候发现的,平时没这么高,所以没发现这些问题
OK, 一个一个回复。
导致截图1所示现象的是一个网络原因,也算是一个小bug吧。由于工作流控制器因为网络原因获取构建job 失败的时候,就会将任务设置为失败。 这个目前为止无法避免,但是已经有在优化了,预计可能在1.13的后面一个版本修复。
截图2 这个是预期中的行为,我来解释一下背后逻辑。 点击工作流重试的时候,是用你当时跑工作流的信息去重试,但是在 1.12版本中,为了应对gitlab版本的升级, zadig加入了每两小时刷新gitlab token的机制。 这个刷新了的token不会刷新到老的工作流中去,所以执行会失败。 解决方法是直接点击运行来重新执行。
截图3 的问题本质与1 是一样的。
好的,谢谢你的回复
关于您回复的截图2的问题,为了应对 gitlab 版本的升级所以才刷新 token这个,是gitlab 升级了什么需要使用这种方法来 work around。
还有麻烦问一下 zadig 1.13 是可以支持 gitlab 14.6 的版本么?
大约在两三个月前,gitlab做了一次升级,取消了可以在集成application时勾选 不expire token这个选项。 这意味着原先代码中默认的长期token不再生效,于是需要定期refresh token。
关于版本问题的话,起码15.2我现在用着没啥问题
明白了,感谢解答!